【kejihao】11月6日消息,李开复博士带队创办的AI 2.0公司零一万物,正式开源发布首款预训练大模型 Yi-34B。
根据 Hugging Face 英文开源社区平台和C-Eval 中文评测的最新榜单,Yi-34B预训练模型以黑马姿态取得了多项 SOTA 国际最佳性能指标认可,成为全球开源大模型“双料冠军”,这也是迄今为止唯一成功登顶 Hugging Face 全球开源模型排行榜的国产模型。
零一万物创始人及CEO李开复博士表示:“零一万物坚定进军全球第一梯队目标,从招的第一个人,写的第一行代码,设计的第一个模型开始,就一直抱着成为‘World\’s No.1’的初衷和决心。我们组成了一支有潜力对标 OpenAI、Google等一线大厂的团队,经历了近半年的厚积薄发,以稳定的节奏和全球齐平的研究工程能力,交出了第一张极具全球竞争力的耀眼成绩单。Yi-34B可以说不负众望,一鸣惊人。”
Yi-34B 登顶全球英文及中文权威榜单No.1
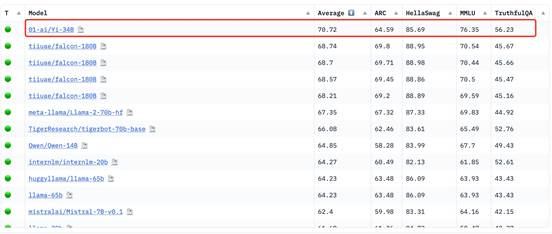
零一万物此次开源发布的Yi系列模型,包含34B和6B两个版本。让人惊艳的是,在Hugging Face 英文测试公开榜单 Pretrained 预训练开源模型排名中,Yi-34B 在各项性能上表现强劲,以70.72的分数位列全球第一,碾压 LLaMA2-70B和 Falcon-180B等众多大尺寸模型。
Hugging Face 是全球最受欢迎的大模型、数据集开源社区,被认为是大模型领域的GitHub,在大模型英文能力测试中具有相当权威性。对比参数量和性能,Yi-34B相当于只用了不及LLaMA2-70B一半、Falcon-180B五分之一的参数量,取得了在各项测试任务中超越全球领跑者的成绩。凭借出色表现,跻身目前世界范围内开源最强基础模型之列。
Hugging Face Open LLM Leaderboard (pretrained) 大模型排行榜,Yi-34B高居榜首(2023年11月5日)
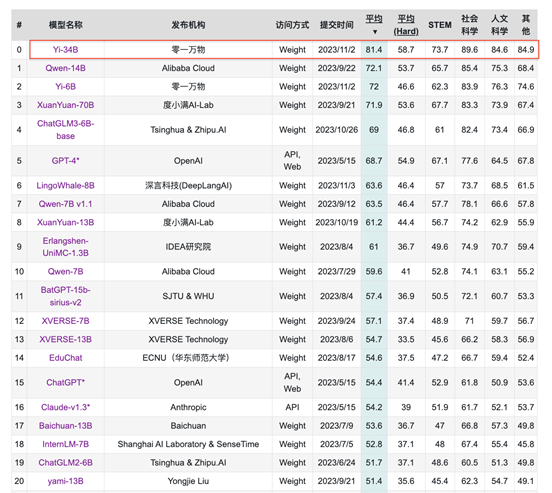
作为国产优质大模型, Yi-34B更“懂”中文。在C-Eval中文权威榜单排行榜上超越了全球所有开源模型。对比大模型标杆GPT-4,在CMMLU、E-Eval、Gaokao 三个主要的中文指标上,Yi-34B 也具有绝对优势,凸显中文世界的优异能力,更好地满足国内市场需求。
C-Eval 排行榜:公开访问的模型,Yi-34B 全球第一(2023年11月5日)
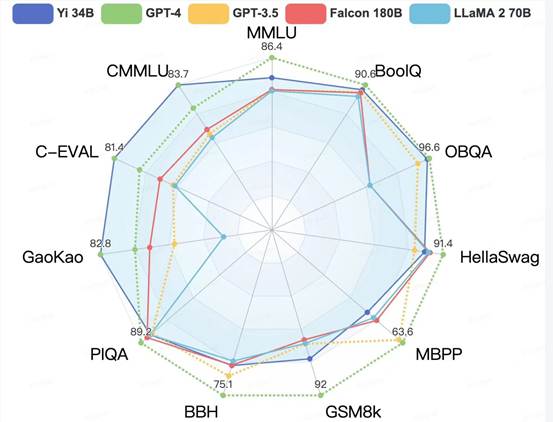
从更为全面的评估看,在全球大模型各项评测中最关键的 “MMLU”(Massive Multitask Language Understanding 大规模多任务语言理解)、BBH等反映模型综合能力的评测集上,Yi-34B 同样表现突出,在通用能力、知识推理、阅读理解等多项指标评比中全部胜出,与 Hugging Face 评测高度一致。

各评测集得分:Yi 模型 v.s. 其他开源模型
但和 LLaMA2一样,Yi系列模型在GSM8k、MBPP 的数学和代码评测表现略逊GPT模型。由于零一万物的技术路线倾向于在预训练阶段尽可能保留模型的通用能力,因此没有加入过多的数学和代码数据。研究团队此前在《Mammoth: Building math generalist models through hybrid instruction tuning》等研究工作中针对数学方向进行过深度探索,在未来,零一万物的系列开源计划中将推出代码能力和数学能力专项的继续训练模型。
全球最长200K上下文窗口,40万字文本极速处理,直接开源
值得注意的是,此次开源的Yi-34B模型,将发布全球最长、可支持200K 超长上下文窗口(context window)版本,可以处理约40万汉字超长文本输入。相比之下,OpenAI的GPT-4上下文窗口只有32K,文字处理量约2.5万字。今年三月,硅谷知名 AI 2.0 创业公司Anthropic的Claude2-100K 将上下文窗口扩展到了100K规模,零一万物直接加倍,并且是第一家将超长上下文窗口在开源社区开放的大模型公司。
在语言模型中,上下文窗口是大模型综合运算能力的金指标之一,对于理解和生成与特定上下文相关的文本至关重要,拥有更长窗口的语言模型可以处理更丰富的知识库信息,生成更连贯、准确的文本。
此外,在文档摘要、基于文档的问答等下游任务中,长上下文的能力发挥着关键作用,行业应用场景广阔。在法律、财务、传媒、档案整理等诸多垂直场景里,更准确、更连贯、速度更快的长文本窗口功能,可以成为人们更可靠的AI助理,让生产力迅猛提升。然而,受限于计算复杂度、数据完备度等问题,上下文窗口规模扩充从计算、内存和通信的角度存在各种挑战,因此大多数发布的大型语言模型仅支持几千tokens的上下文长度。
为了解决这个限制,零一万物技术团队实施了一系列优化,包括:计算通信重叠、序列并行、通信压缩等。通过这些能力增强,实现了在大规模模型训练中近100倍的能力提升,也为Yi系列模型上下文规模下一次跃升储备了充足“电力”。
Yi-34B的200K上下文窗口直接开源,不仅能提供更丰富的语义信息,理解超过1000页的PDF文档,让很多依赖于向量数据库构建外部知识库的场景,都可以用上下文窗口来进行替代。Yi-34B的开源属性也给想要在更长上下文窗口进行微调的开发者提供了更多的可能性。
AI Infra 是大模型核心护城河,实测实现40%训练成本下降
AI Infra(AI Infrastructure 人工智能基础架构技术)主要涵盖大模型训练和部署提供各种底层技术设施,包括处理器、操作系统、存储系统、网络基础设施、云计算平台等等,是模型训练背后极其关键的“保障技术”,这是大模型行业至今较少受到关注的硬技术领域。
李开复曾经表示,“做过大模型Infra的人比做算法的人才更稀缺”。在打造“World\’s No.1\”梯队时,超强的Infra 能力是大模型研发的核心护城河之一。如果说训练大模型是登山,Infra的能力定义了大模型训练算法和模型的能力边界,也就是“登山高度”的天花板。在芯片、GPU等算力资源紧缺的当下,安全和稳定成为大模型训练的生命线。零一万物的 Infra 技术通过“高精度”系统、弹性训和接力训等全栈式解决方案,确保训练高效、安全地进行。
凭借强大的 AI Infra 支撑,零一万物团队能实现超越行业水平的训练效果,Yi-34B模型训练成本实测下降40%,实际训练完成达标时间与预测的时间误差不到一小时,进一步模拟上到千亿规模训练成本可下降多达50%。截至目前,零一万物Infra能力实现故障预测准确率超过90%,故障提前发现率达到99.9%,不需要人工参与的故障自愈率超过95%,有力保障了模型训练的顺畅进行。
在 Yi 开源模型的全球首发日,零一万物CEO李开复也宣布,在完成 Yi-34B 预训练的同时,已经旋即启动下一个千亿参数模型的训练。“零一万物的数据处理管线、算法研究、实验平台、GPU 资源和 AI Infra 都已经准备好,我们的动作会越来越快”。
深研“规模化训练实验平台”,从“粗放炼丹”进阶到 “科学训模”
耀眼成绩的取得,源于零一万物潜心数月练就的大模型 “科学训模”方法论。
众所周知,大模型效果依赖于更多、更高质量的数据,零一万物在数据处理管线上可谓“不惜成本”。由前Google大数据和知识图谱专家领衔的数据团队,凭对数据的深度理解与认知,结合大量数据处理实验,建设了高效、自动、可评价、可扩展的智能数据处理管线。
不仅如此,经过几个月大量的建模和实验,零一万物自研出一套“规模化训练实验平台”,用来指导模型的设计和优化。数据配比、超参搜索、模型结构实验都可以在小规模实验平台上进行,对34B模型每个节点的预测误差都可以控制在0.5%以内。掌握了更强的模型预测能力,从而大大减少了进行对比实验需要的资源,也减少了训练误差对于计算资源的浪费。
数据处理管线和加大规模预测的训练能力建设,把以往的大模型训练碰运气的“炼丹”过程变得极度细致和科学化,不仅保证了目前发布Yi-34B、Yi-6B模型的高性能,也为未来更大规模模型的训练压缩了时间和成本,有能力以领先于行业的速度,将模型规模“丝滑”扩大到数倍。
零一万物团队首度亮相,卧虎藏龙齐聚行业巨头人才
零一万物的团队卧虎藏龙,成员来自Google、微软、阿里巴巴、百度、字节跳动、腾讯等国内外顶级企业背景,并持续延揽全球范围内最优秀的华人AI精英。
零一万物算法和模型团队成员,有论文曾被GPT-4引用的算法大拿,有获得过微软内部研究大奖的优秀研究员,曾获得过阿里CEO特别奖的超级工程师。总计在ICLR、NeurIPS、CVPR、ICCV等知名学术会议上发表过大模型相关学术论文100余篇。
零一万物技术副总裁及AI Alignment负责人是 Google Bard/Assistant 早期核心成员,主导或参与了从 Bert、LaMDA 到大模型在多轮对话、个人助理、AI Agent 等多个方向的研究和工程落地;首席架构师曾在Google Brain与Jeff Dean、Samy Bengio等合作,为TensorFlow的核心创始成员之一。
首次发布的背后主力战将,零一万物技术副总裁及 Pretrain 负责人黄文灏是通用人工智能 AGI 的信仰者,他曾先后任职于微软亚洲研究院和智源研究院。 在微软从事AI Agent研究工作时,得到微软创始人比尔•盖茨和CEO 萨提亚•纳德拉的高度赞扬。
而支持 Yi 模型训练保障交付的零一万物技术副总裁及AI Infra负责人戴宗宏,是前华为云 AI CTO 及技术创新部长、前阿里达摩院 AI Infra 总监。Infra核心团队主要来自于阿里、华为、微软、商汤,是AI 多领域具有高水平研究及系统研发能力的顶尖专家,曾经参与支持了4个千亿参数大模型规模化训练,管理过数万张GPU卡,夯实了端到端的全栈AI技术能力,零一万物可说是具备一支行业内少有的 AI Infra “技术天团”。
打造更多ToC Super App,培育新型“AI-first”创新生态
零一万物认为,34B的模型尺寸在开源社区属于稀缺的“黄金比例”尺寸。相比目前开源社区主流的7B、13B等尺寸,34B模型具备更优越的知识容量、下游任务的容纳能力和多模态能力,也达到了大模型 “涌现”的门槛。
在精度上,不少开发者都表示7B、13B开源模型在很多场景下无法满足需求,追求更好的性能需要使用30B以上的模型,但一直没有合适的选择,高质量的Yi-34B的出现,顺利解决了开源社群这一刚性需求。
而比起更大的 50B至70B,34B是单卡推理可接受的模型尺寸的上限,训练成本对开发者更友好,经过量化的模型可以在一张消费级显卡(如4090)上进行高效率的推理,对开发者操作服务部署有很大的优势。
接下来,零一万物将基于Yi系列大模型,打造更多To C超级应用。李开复强调,“AI 2.0是有史以来最大的科技革命,它带来的改变世界的最大机会一定是平台和技术,正如PC时代的微软Office,移动互联网时代的微信、抖音、美团一样,商业化爆发式增长概率最高的一定是ToC应用。零一万物邀请开发者社群跟我们一起搭建Yi开源模型的应用生态系,协力打造AI 2.0时代的超级应用。”
目前,Yi系列模型已在 Hugging Face、ModelScope、GitHub 三大全球开源社区平台正式上线,同时开放商用申请,给开发者在使用LLM的过程中提供更多、更优质的选择。
本次开源的基座模型包括200K上下文窗口的基座模型,基座模型进行了比较均衡的IQ和EQ的配置,保留了后续进行不同方向微调的可能性。为了能让语言模型有更好的应用效果,广大开发者可以基于基座模型进行微调,GitHub 01Yi 开源网页上已经提供了简单的微调代码,同时模型和主流语言模型微调框架兼容,开发者可以自行进行适配。
接下来,零一万物还将基于Yi 基座模型,快节奏开源发布一系列的量化版本、对话模型、数学模型、代码模型和多模态模型等,邀请开发者积极投入,共同促进语言模型开源社区的繁荣发展,培育新型“AI-first”创新生态体系。
希望有更多的开发者使用Yi系列模型,打造自己场景中的“ChatGPT”,引领下一代前沿创新和商业模型,探索走向通用人工智能的先进能力。
