机器学习的一个重要研究就是提升模型的泛化性,并且在训练模型的时候一个假设,即训练集数据的分布和测试集相同。
然而,模型面对的输入数据来自于真实世界,也就是不稳定的、会进化的、数据分布会随环境发生变化。
虽然对人类来说,这个问题十分好解决,例如网络用语层出不穷,但每个人都能很快地接受,并熟练地运用起来,但对机器来说却很难。
人类可以通过重用相关的先前知识来迅速适应和学习新知识,如果把这个思路用在机器学习模型上,首先需要弄清楚如何将知识分离成易于重新组合的模块,以及如何修改或组合这些模块,以实现对新任务或数据分布的建模。
基于这个问题,图灵奖得主Yoshua Bengio最近在arxiv上公开了一篇论文,提出了一个模块化的架构,由一组独立的模块组成,这些模块相互对抗,利用key-value注意力机制找到相关的知识。研究人员在模块和注意力机制参数上采用元学习方法,以强化学习的方式实现快速适应分布的变化或新任务。

这个团队研究这样的模块化架构是否可以帮助将知识分解成不可更改和可重用的部分,以便得到的模型不仅更具样本效率,而且还可以在各种任务分布之间进行泛化。
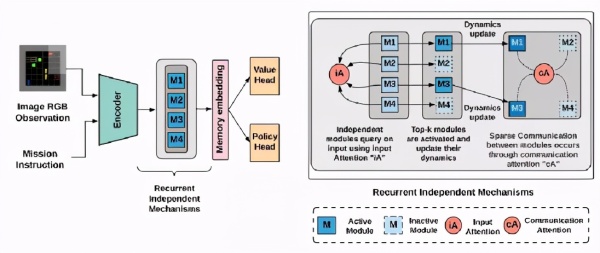
该模型基于一个包含一组独立模块和竞争模块的循环独立机制(RIMs)体系结构。在这种设置中,每个模块通过注意力独立行动,并与其他模块交互。不同的模块通过输入注意力处理输入的不同部分,而模块之间的上下文关系通过交流注意力建立。
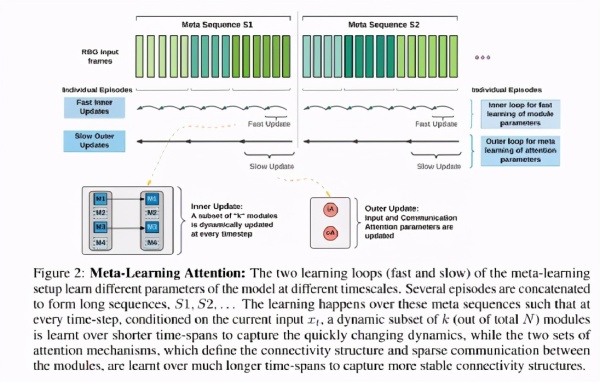
研究人员还展示了如何利用元学习在不同的时间尺度上以不同的速度训练网络的不同组成部分,从而捕捉到底层分布的快速变化和缓慢变化的方面。
因此,该模型既有快速学习阶段,也有慢速学习阶段。
在快速fast学习中,快速更新激活的模块参数以捕获任务分布中的变化。
在缓慢slow学习中,这两套注意力机制的参数更新频率较低,以捕捉任务分布中更稳定的方面。
该团队评估了他们提出的 Meta-RIMs 网络在从 MiniGrid 和 BabyAI 套件的各种环境。他们选择平均回报率和平均成功率作为衡量标准,并用两个基准模型对 Meta-RIMs 网络进行比较: Vanilla LSTM 模型和模块化网络(modular network)。
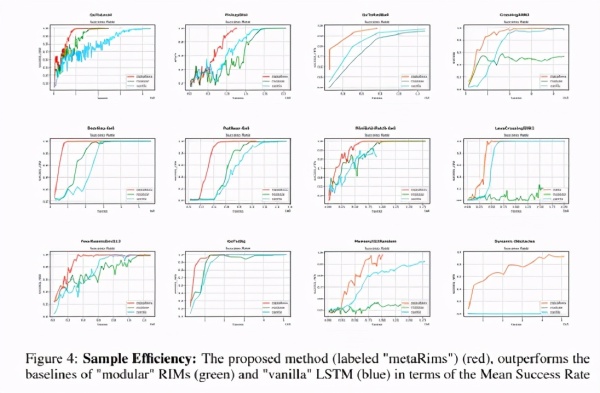
结果表明,所提出的方法能够提高样本效率,导致更好地推广到训练分布的系统性变化的策略。
此外,这种方法能够更快地适应新的发行版本,并且通过重复利用从类似的以前学过的任务中获得的知识,以渐进的方式训练强化学习的学习体,形成更好的知识学习方法。
该研究成功地利用模块化结构上的元学习和稀疏通信来捕捉潜在机制的短期和长期方面,证实了元学习和基于注意力的模块化可以导致更好的样本效率、分布外的泛化和迁移学习。
Reddit网友idea撞车?
论文一出,Reddit上立马引发热议。
一个小哥发评论说感觉相当难受了,我做这个4年了,今年就要发表,但还是被领先了。后来又补充说并不是一模一样的工作,但是非常接近。
这也引来了无数安慰,相似的结论可能来源于不同的方法,每个方法都是有价值的。
还有网友认为,你的实力已经可以和Bengio及他的团队匹敌了,这是一件好事!并且有其他人和你面对同一件事有不同的想法,也许也能给你启发,促进工作。
知乎上也有网友对此提出问题。
有网友表示,两篇论文全撞车,CV太卷了,当做的论文和大佬撞车时候,完全没有反抗的余地,因为别人的工作是无懈可击的。有机会一定要挖坑,不去填坑。
目前深度学习的一些工作已经到了拼手速的地步,当BERT一出,各种基于BERT的工作层出不穷,只是一个验证的工作,而不能对同行有一定的启发。
毕竟牛顿和莱布尼茨还在争夺微积分,普通人撞车也是很正常的。
你有论文撞车过吗?
