在训练人工「智障」的时候,AI最后经常会学到一些莫名其妙的方式来完成人类的的任务。
有一些AI就会去学习如何通过「卡bug」来快速通关。

还有一些AI学会了「只要把游戏暂停了,我就不会输」这个终极哲学。
AI也想「躺平」
为了让模型能够提高准确性,通常会设置相应的奖励,但有时候模型在前期就发现了能够获得奖励的「捷径」。
但凡AI尝到了甜头,它就会一直选择去走这个「捷径」,不再去学习更困难的知识或者方法。
来自北京大学的研究人员在训练语言模型的时候就发现:AI虽然能回答正确,但是它搞不明白为什么答案是对的,只知道遇到某类问题用这个回答就可以了。
于是,研究人员决定要把AI「扶起来」,让它们「努力学习」不能偷懒。

论文地址: https://arxiv.org/pdf/2106.01024.pdf
这篇论文已经发表在arxiv上,作者是来自北京大学王选计算机研究所和北京大学计算语言学教育部重点实验室的Yuxuan Lai, Chen Zhang, Yansong Feng , Quzhe Huang,和Dongyan Zhao(赵东岩)
为什么AI总想去「躺平」?
尽管有些研究已经发现了AI总爱「躺平」的现象,但是他们并没有发现这个现象和数据集中的「捷径」问题有关。
为此,论文提出了一个经过标注的全新数据集,其中包括对一个问题的「捷径版」和「挑战版」两种回答。
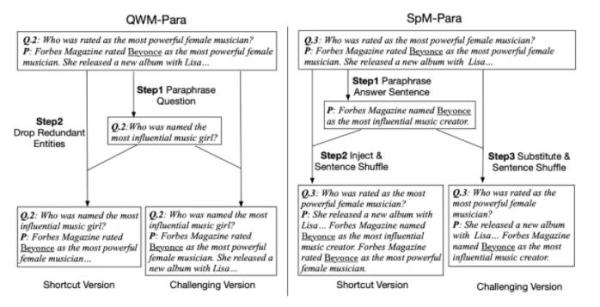
数据集使用「释义」( paraphrasing )作为更复杂和更深入答案的标准,因为想要表达出学到的知识,语义理解是必要的。相比之下,「捷径」的答案是有如日期或其他关键字生成的,但没有任何上下文或推理。
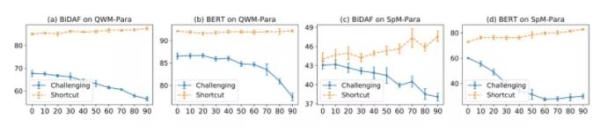
研究人员发现,训练集中「捷径版」样本越高,就越会阻碍模型学到「释义」从而去解决具有挑战性的问题。而模型在回答「捷径版」问题时的表现则基本稳定。
文章表明,当训练集中有足够多的「挑战版」问题时,模型不仅能更好地理解「挑战版」问题,而且也能正确回答「捷径版」问题。
AI是如何学会「躺平」的?
文章表示,在训练的早期阶段,模型往往会找到最简单的方法达到梯度下降从而拟合训练数据。而且由于「捷径」需要较少的计算资源来学习,因此拟合这些技巧会变成一个优先事项。
之后,由于模型学会的「捷径」可用于正确回答大部分训练问题,因此剩余的问题便无法激励模型继续去探索「挑战版」问题需要的复杂解决方法。
有没有办法把AI「扶起来」?
除了NLP架构本身的问题外,也很可能是训练过程中标准优化和资源保护的结果,以及让模型在短时间内以有限的资源去获得结果的压力。
如文章所说的那样,数据预处理领域可能需要考虑将数据中的「捷径」视为一个亟待解决的问题,或者是修改 NLP 架构从而达到优先考虑更具挑战性的数据的效果。
