上次介绍了HDFS的简单操作,今天进入HDFS中的Java和Python的API操作,后面可能介绍Scala的相关的。
在讲Java API之前介绍一下使用的IDE——IntelliJ IDEA ,我本人使用的是2020.3 x64的社区版本。
Java API
创建maven工程,关于Maven的配置,在IDEA中,Maven下载源必须配置成阿里云。
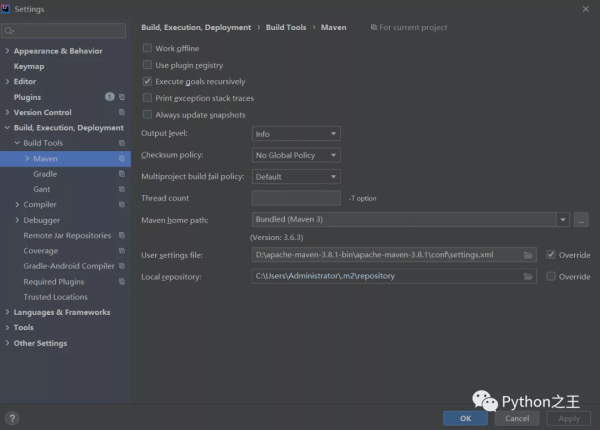
在对应的D:apache-maven-3.8.1-binapache-maven-3.8.1confsettings.xml需要设置阿里云的下载源。
下面创建maven工程,添加常见的依赖
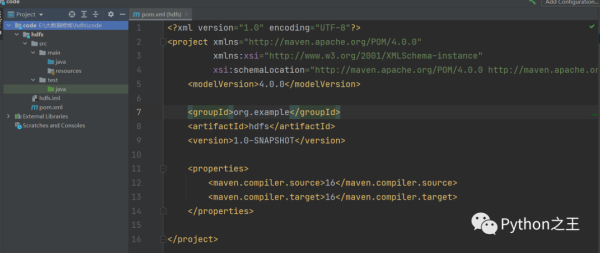
添加hadoop-client依赖,版本最好和hadoop指定的一致,并添加junit单元测试依赖。
org.apache.hadoophadoop-common3.1.4org.apache.hadoophadoop-hdfs3.1.4org.apache.hadoophadoop-client3.1.4junitjunit4.11 HDFS文件上传
在这里编写测试类即可,新建一个java文件:main.java
这里的FileSyste一开始是本地的文件系统,需要初始化为HDFS的文件系统
importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importorg.junit.Test;importjava.net.URI;publicclassmain{@TestpublicvoidtestPut()throwsException{//获取FileSystem类的方法有很多种,这里只写一种(比较常用的是使URI)Configurationconfiguration=newConfiguration();//user是Hadoop集群的账号,连接端口默认9000FileSystemfileSystem=FileSystem.get(newURI(\”hdfs://192.168.147.128:9000\”),configuration,\”hadoop\”);//将f:/stopword.txt上传到/user/stopword.txtfileSystem.copyFromLocalFile(newPath(\”f:/stopword.txt\”),newPath(\”/user/stopword.txt\”));fileSystem.close();}}
在对应的HDFS中,就会看见我刚刚上传的机器学习相关的停用词。
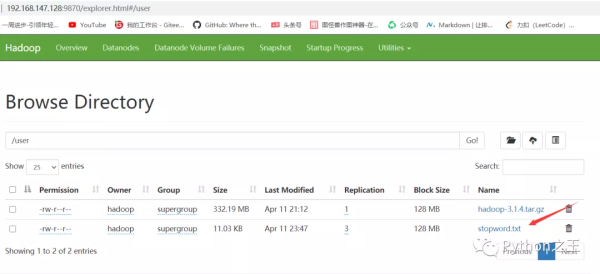 HDFS文件下载
HDFS文件下载
由于每次都需要初始化FileSystem,比较懒的我直接使用@Before每次加载。
HDFS文件下载的API接口是copyToLocalFile,具体代码如下。
@TestpublicvoidtestDownload()throwsException{Configurationconfiguration=newConfiguration();FileSystemfileSystem=FileSystem.get(newURI(\”hdfs://192.168.147.128:9000\”),configuration,\”hadoop\”);fileSystem.copyToLocalFile(false,newPath(\”/user/stopword.txt\”),newPath(\”stop.txt\”),true);fileSystem.close();System.out.println(\”over\”);} Python API
下面主要介绍hdfs,参考:https://hdfscli.readthedocs.io/
我们通过命令pip install hdfs安装hdfs库,在使用hdfs前,使用命令hadoop fs -chmod -R 777 / 对当前目录及目录下所有的文件赋予可读可写可执行权限。
>>>fromhdfs.clientimportClient>>>#2.X版本port使用500703.x版本port使用9870>>>client=Client(\’http://192.168.147.128:9870\’)>>>client.list(\’/\’)#查看hdfs/下的目录[\’hadoop-3.1.4.tar.gz\’]>>>client.makedirs(\’/test\’)>>>client.list(\’/\’)[\’hadoop-3.1.4.tar.gz\’,\’test\’]>>>client.delete(\”/test\”)True>>>client.download(\’/hadoop-3.1.4.tar.gz\’,\’C:\\Users\\YIUYE\\Desktop\’)\’C:\\Users\\YIUYE\\Desktop\\hadoop-3.1.4.tar.gz\’>>>client.upload(\’/\’,\’C:\\Users\\YIUYE\\Desktop\\demo.txt\’)>>>client.list(\’/\’)\’/demo.txt\’>>>client.list(\’/\’)[\’demo.txt\’,\’hadoop-3.1.4.tar.gz\’]>>>#上传demo.txt内容:Hello hdfs>>>withclient.read(\”/demo.txt\”)asreader:…print(reader.read())b\’Hello hdfs \’
相对于Java API,Python API连接实在简单。
