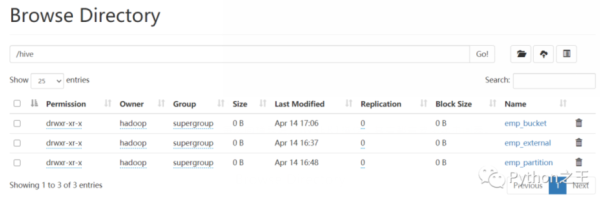
在Hive数据仓库中,重要点就是Hive中的四个表。Hive 中的表分为内部表、外部表、分区表和分桶表。
内部表
默认创建的表都是所谓的内部表,有时也被称为管理表。因为这种表,Hive 会(或多或少地)控制着数据的生命周期。Hive 默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。当我们删除一个管理表时,Hive 也会删除这个表中数据。管理表不适合和其他工具共享数据。
具体的内部表创建命令
CREATETABLEemp(empnoINT,enameSTRING,jobSTRING,mgrINT,hiredateTIMESTAMP,salDECIMAL(7,2),commDECIMAL(7,2),deptnoINT)ROWFORMATDELIMITEDFIELDSTERMINATEDBY\” \”;–分隔符 外部表
外部表称之为EXTERNAL_TABLE;其实就是,在创建表时可以自己指定目录位置(LOCATION);如果删除外部表时,只会删除元数据不会删除表数据;
具体的外部表创建命令,比内部表多一个LOCATION而已。
CREATEEXTERNALTABLEemp_external(empnoINT,enameSTRING,jobSTRING,mgrINT,hiredateTIMESTAMP,salDECIMAL(7,2),commDECIMAL(7,2),deptnoINT)ROWFORMATDELIMITEDFIELDSTERMINATEDBY\” \”LOCATION\’/hive/emp_external\’; 「内部表和外部表的区别:」 创建内部表时:会将数据移动到数据仓库指向的路径; 创建外部表时:仅记录数据所在路径,不对数据的位置做出改变; 删除内部表时:删除表元数据和数据; 删除外部表时,删除元数据,不删除数据。 分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
具体的分区表创建命令如下,比外部表多一个PARTITIONED。PARTITIONED英文意思就是分区的,需要指定表中的其中一个字段,这个就是根据该字段的不同,划分不同的文件夹。
CREATEEXTERNALTABLEemp_partition(empnoINT,enameSTRING,jobSTRING,mgrINT,hiredateTIMESTAMP,salDECIMAL(7,2),commDECIMAL(7,2))PARTITIONEDBY(deptnoINT)–按照部门编号进行分区ROWFORMATDELIMITEDFIELDSTERMINATEDBY\” \”LOCATION\’/hive/emp_partition\’; 分桶表
分区在HDFS上的表现形式是一个目录,分桶则是一个单独的文件。分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。
具体的分桶表创建命令如下,比分区表的不同在于CLUSTERED。CLUSTERED英文意思就是群集的。分桶操作和分区一样,需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)
CREATEEXTERNALTABLEemp_bucket(empnoINT,enameSTRING,jobSTRING,mgrINT,hiredateTIMESTAMP,salDECIMAL(7,2),commDECIMAL(7,2),deptnoINT)CLUSTEREDBY(empno)SORTEDBY(empnoASC)INTO4BUCKETS–按照员工编号散列到四个bucket中ROWFORMATDELIMITEDFIELDSTERMINATEDBY\” \”LOCATION\’/hive/emp_bucket\’; 「分区表和分桶表的区别:」
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似;分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件,所以数据的准确性也高很多。
分桶表的建表有三种方式:直接建表,CREATE TABLE LIKE 和 CREATE TABLE AS SELECT
注:不能直接向桶表中加载数据,需要使用insert语句插入数据,因此只要见到load data 到桶表的,基本是乱来的。分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce,因此分桶的时间是比较长的,因为要进行MapReduce操作。
根据上面命令,成功创建了内部表、外部表、分区表和分桶表。
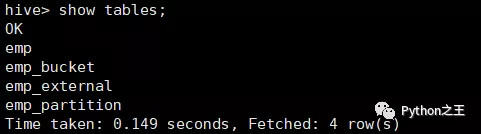
下面依次插入数据到四张表,emp.txt具体内容如下:
7369SMITHCLERK79021980-12-1700:00:00800.00207499ALLENSALESMAN76981981-02-2000:00:001600.00300.00307521WARDSALESMAN76981981-02-2200:00:001250.00500.00307566JONESMANAGER78391981-04-0200:00:002975.00207654MARTINSALESMAN76981981-09-2800:00:001250.001400.00307698BLAKEMANAGER78391981-05-0100:00:002850.00307782CLARKMANAGER78391981-06-0900:00:002450.00107788SCOTTANALYST75661987-04-1900:00:001500.00207839KINGPRESIDENT1981-11-1700:00:005000.00107844TURNERSALESMAN76981981-09-0800:00:001500.000.00307876ADAMSCLERK77881987-05-2300:00:001100.00207900JAMESCLERK76981981-12-0300:00:00950.00307902FORDANALYST75661981-12-0300:00:003000.00207934MILLERCLERK77821982-01-2300:00:001300.0010
具体的插入数据命令如下所示:
##内部表loaddatalocalinpath\”emp.txt\”intotableemp;##外部表loaddatalocalinpath\”emp.txt\”intotableemp_external;##分区表LOADDATALOCALINPATH\”emp.txt\”OVERWRITEINTOTABLEemp_partitionPARTITION(deptno=10);LOADDATALOCALINPATH\”emp.txt\”OVERWRITEINTOTABLEemp_partitionPARTITION(deptno=20);LOADDATALOCALINPATH\”emp.txt\”OVERWRITEINTOTABLEemp_partitionPARTITION(deptno=30);##分桶表–启用桶表sethive.enforce.bucketing=true;–限制对桶表进行load操作sethive.strict.checks.bucketing=true;INSERTINTOTABLEemp_bucketSELECT*FROMemp;–这里的emp表就是一张普通的雇员表
每次向桶表进行INSERT操作,其实都需要创建中间表。